Inverse Fehlerfunktion Rechner
Online Rechner zur Berechnung der inversen Fehlerfunktion erfi(x)
Inverse Fehlerfunktion Rechner
Die Inverse Fehlerfunktion
Die inverse Fehlerfunktion erfi(x) berechnet Quantile der Normalverteilung und ist wesentlich für statistische Inferenz und kritische Werte.
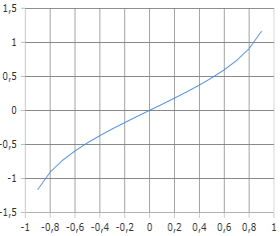
Inverse Fehlerfunktion Kurve
Die Kurve zeigt die inverse Abbildung von Wahrscheinlichkeiten.
Monoton steigende Funktion mit Symmetrie um den Ursprung.
Was ist die Inverse Fehlerfunktion?
Die inverse Fehlerfunktion erfi(x) ist die Umkehrfunktion von erf(x):
- Definition: erfi(y) ist das x mit erf(x) = y
- Quantilfunktion: Berechnet Normalverteilungsquantile
- Bereich: -1 ≤ y ≤ 1
- Anwendung: Statistische Hypothesentests, Konfidenzintervalle, Normalquantile
- Signifikanz: Brücke zwischen Wahrscheinlichkeit und z-Werten
- Verwandt mit: Normalverteilungsquantile, Probit-Funktion
Normalverteilungsquantile und statistische Anwendungen
Die inverse Fehlerfunktion ist fundamental für Normalverteilungsberechnungen:
Normal-Quantil Interpretation
- z-Score: erfi(p) = √2 × Φ⁻¹((p+1)/2)
- Perzentile: Konvertierung Wahrscheinlichkeiten zu z-Werten
- Kritische Werte: Statistische Test-Schwellenwerte
- Konfidenzgrenzen: Intervallgrenzberechnung
Probit-Analyse
- Probit-Funktion: Link-Funktion in Regression
- Dosis-Antwort: Biologische Prüfungsanalyse
- Binäre Ergebnisse: Logistische Regression Alternative
- Schwellenwert-Modelle: Latente Variable Modellierung
Anwendungen der Inversen Fehlerfunktion
Die inverse Fehlerfunktion ist unverzichtbar für Statistik und wissenschaftliche Rechnung:
Statistische Inferenz
- Normalverteilungsquantile
- Kritische Werte für z-Tests
- Konfidenzintervallberechnung
- p-Wert-Transformationen
Biometrische Analyse
- Probit-Regression-Modellierung
- Dosis-Antwort Kurven
- LD50 und EC50 Berechnungen
- Toleranzverteilungsanalyse
Monte-Carlo Simulation
- Normalzahlengenerierung
- Box-Muller Transformation
- Gauß-Prozess Simulation
- Stochastische Modellierung
Ingenieuranwendungen
- Qualitätskontroll-Spezifikationen
- Zuverlässigkeits-Ingenieurswesen
- Optimierungs-Algorithmen
- Signal-Verarbeitungs-Filter
Formeln für die Inverse Fehlerfunktion
Inverse Funktionsdefinition
x ist das Argument mit erf Wert = y
Normalverteilungs-Beziehung
Verbindung zu Normal-Quantilfunktion Φ⁻¹
Probit-Funktion Verbindung
Link zu Probit-Funktion für Wahrscheinlichkeit p
Inverse Beziehung
Fundamentale Identität für Umkehrfunktionen
Reihenentwicklung (Kleine y)
Taylor-Reihe für kleine Argumente
Symmetrie-Eigenschaft
Ungerade Funktion Eigenschaft
Beispielrechnungen für die Inverse Fehlerfunktion
Beispiel 1: Standardnormal-Quantil
Aufgabe
- Standardnormalverteilung: N(0,1)
- Gesucht: 95. Perzentil (z₀.₀₅)
- Wahrscheinlichkeit: 95% = 0.95
Berechnung
Beispiel 2: Probit-Analyse (Dosis-Antwort)
Problem
- Dosis-Antwort Studie: Toxizitätsbewertung
- Gesucht: Probit-Wert für 50% Antwort
- Antwort-Wahrscheinlichkeit: p = 0.5
Lösung
Beispiel 3: Rechner Standardwert
Aufgabe
Berechnungsergebnis
Inverse Fehlerfunktion Werte
| y (erf-Wert) | erfi(y) | Normal-Perzentil | Statistische Nutzung |
|---|---|---|---|
| 0.0 | 0.0000 | 50. Perzentil | Median |
| 0.3 | 0.2724 | 65. Perzentil | Mäßige Signifikanz |
| 0.6 | 0.5951 | 80. Perzentil | Moderate Signifikanz |
| 0.9 | 1.1631 | 95. Perzentil | Hohe Signifikanz |
| 0.95 | 1.3859 | 97.5. Perzentil | Sehr hohe Signifikanz |
| 0.99 | 1.8214 | 99.5. Perzentil | Extreme Signifikanz |
Mathematische Grundlagen der Inversen Fehlerfunktion
Die inverse Fehlerfunktion erfi(x) ist die Umkehrfunktion der Fehlerfunktion und bildet die mathematische Grundlage für die Berechnung von Normalverteilungsquantilen. Sie ist unverzichtbar für statistische Inferenz, Hypothesentests und Konfidenzintervallkonstruktion.
Historische Entwicklung
Die Entwicklung der inversen Fehlerfunktion verlief parallel zu Fortschritten in der Wahrscheinlichkeitstheorie:
- Carl Friedrich Gauss (1809): Normalverteilungstheorie Grundlagen
- Pierre-Simon Laplace (1812): Grenzwertsätze und Normale Approximationen
- Francis Galton (1880er): Praktische Anwendungen in Biometrie
- Ronald Fisher (1920er): Statistische Inferenz und Hypothesentests
- Moderne Ära: Numerische Algorithmen und Computerimplementierung
Mathematische Eigenschaften
Die inverse Fehlerfunktion besitzt wichtige analytische Eigenschaften:
Analytische Eigenschaften
- Ungerade Funktion: erfi(-y) = -erfi(y)
- Monotonie: Streng monoton steigend
- Definitionsbereich: -1 ≤ y ≤ 1
- Wertebereich: -∞ < erfi(y) < +∞
Berechnungsaspekte
- Reihenentwicklung: Für kleine Argumente
- Asymptotische Expansion: Für große Argumente
- Rationale Approximationen: Für effiziente Berechnung
- Newton-Raphson: Iterative Wurzelfindung
Verbindungen zu anderen Funktionen
Die inverse Fehlerfunktion ist mit vielen wichtigen statistischen Funktionen verwandt:
Statistische Funktionen
- Normalquantil: Φ⁻¹(p) = √2 × erfi(2p-1)
- Probit-Funktion: probit(p) = √2 × erfi(2p-1)
- z-Scores: Kritische Werte für Hypothesentests
- Konfidenzgrenzen: Intervallgrenzberechnung
Spezielle Funktionen
- Dawson-Integral: Verwandte Spezialfunktion
- Fresnel-Integrale: Verbindung über komplexe Analyse
- Gamma-Funktion: Probabilistische Darstellung
- Hypergeometrische: Reihenentwicklungen
Anwendungen in modernen Wissenschaften
Statistik & Inferenz
- Hypothesentest kritische Werte
- Konfidenzintervallgrenzen
- p-Wert-Berechnungen
- Stichprobengrößenbestimmung
Angewandte Wissenschaften
- Qualitätskontrolle und Six Sigma
- Biostatistik und klinische Studien
- Ökonometrie und Finanzwesen
- Zuverlässigkeits-Ingenieurswesen
Zusammenfassung
Die inverse Fehlerfunktion ist ein Eckpfeiler des statistischen Rechnens und der Datenanalyse. Ihre Rolle bei der Konvertierung von Wahrscheinlichkeiten zu Normalverteilungsquantilen macht sie unverzichtbar für Hypothesentests, Konfidenzintervalle und statistische Modellierung. Von Qualitätskontrolle in der Fertigung bis zur klinischen Versuchsanalyse in der Medizin bietet sie die mathematische Grundlage für evidenzbasierte Entscheidungsfindung.
|
|
|
|